
Les fondamentaux de l’IA générative
Comprendre les bases de l'IA générative, c'est découvrir comment les machines peuvent créer du contenu original et innovant à partir de données existantes.
Cette exploration vous permettra de saisir les mécanismes sous-jacents qui alimentent cette capacité créative.
En apprenant les fondamentaux de l'IA générative, vous aurez une vision claire de la manière dont les machines peuvent être utilisées pour générer du texte, ouvrant ainsi la voie à de nouvelles applications et opportunités passionnantes.
Les modèles de langage et les Transformers
Les modèles de langage et les Transformers sont au cœur de l'IA générative, mais comment fonctionnent-ils réellement ?
En plongeant dans cette section, vous découvrirez les mécanismes qui permettent à ces algorithmes de comprendre et de générer du langage naturel.
Nous utiliserons un exemple concret - comment organiser rationnellement une bibliothèque - pour illustrer les concepts de bases des modèles de langage, des bases de données vectorielles et des Transformers.
Chat GPT et les autres
Parmi les modèles de langage les plus célèbres figure Chat GPT, mais il n'est pas seul dans ce domaine. Chaque jour, une nouvelle solution apparait
Exemples pratiques
Pour illustrer concrètement les possibilités offertes par l'IA générative, nous explorerons une série d'exemples pratiques.
Commençons par les concepts fondamentaux !

L'IA générative : Créer du nouveau à partir d'une question
L'IA générative est une branche de l'intelligence artificielle qui se distingue par sa capacité à créer de nouveaux contenus réalistes, plutôt que de simplement résoudre des problèmes existants. Imaginez un assistant capable de composer un poème, de synthétiser une image de rêve ou de créer une mélodie originale, simplement en suivant vos instructions. C'est le pouvoir de l'IA générative !Fonctionnement :
Le Prompt : Tout commence par une question, appelée "prompt", que vous posez à l'IA. C'est votre directive, votre point de départ.Décodage et recherche : L'IA utilise ses capacités de traitement du langage naturel pour décoder votre prompt et identifier les informations pertinentes dans sa base de connaissance.
Génération de la réponse : L'IA exploite ensuite sa puissance de calcul pour générer le contenu demandé, sous la forme souhaitée : texte, image, vidéo, musique, etc.
Apprentissage et contexte : L'IA prend en compte le contexte de vos interactions et l'intègre dans son processus d'apprentissage. Cela lui permet d'affiner ses réponses et de mieux répondre à vos attentes au fil du temps.
Exemples d'applications :
Littérature : Génération de poèmes, de scripts, de romans, etc.Art numérique : Création d'images, de peintures, de sculptures, etc.
Musique : Composition de morceaux, de mélodies, d'ambiances sonores, etc.
Développement de produits : Conception de prototypes, de modèles virtuels, d'interfaces utilisateur, etc.
L'IA générative ouvre un monde de possibilités créatives et révolutionne de nombreux domaines. Sa capacité à apprendre et à s'adapter en permanence promet un avenir riche en innovations et en découvertes.
Liens utiles :
Introduction à l'IA générativeApplications IA
Une architecture informatique repensée
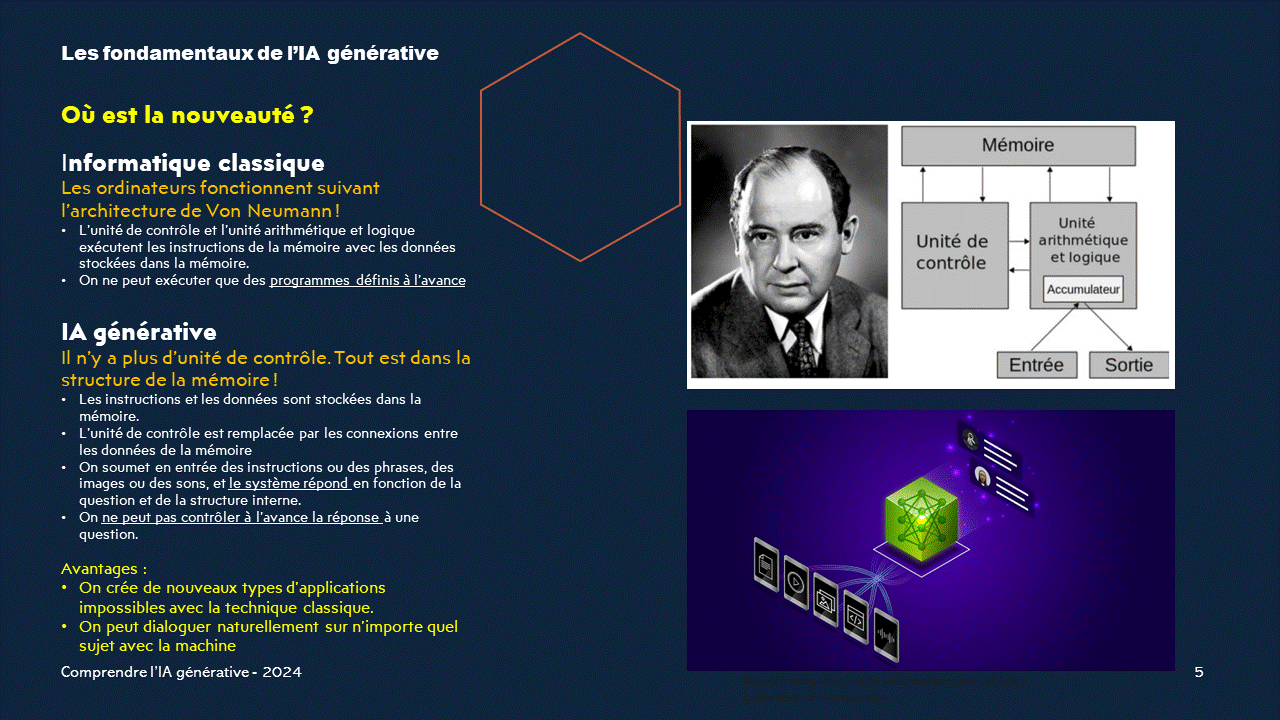
L'IA générative bouleverse le fonctionnement des ordinateurs en s'affranchissant de l'architecture traditionnelle de Von Neumann.La structure de la mémoire et les connexions entre les données prennent le pas sur l'unité de contrôle, permettant une création et une interaction inédites.
Points clés:
Abandon de l'unité de contrôle centraleRéorganisation de la structure de la mémoire et des connexions entre les données
Utilisation de processeurs spécialisés pour accélérer les traitements spécifiques à l'IA
Résultats de cette nouvelle organisation :
Réponses pertinentes et non préprogrammées à l'avance répondant aux questions poséesNouvelles applications et dialogue naturel avec la machine
Exemple concret:
Imaginez un chatbot utilisant l'IA générative. Au lieu de suivre un script prédéfini, il analyse votre question, explore les connexions entre les données de sa mémoire et génère une réponse unique et adaptée à votre demande.Conclusion:
L'IA générative ouvre la voie à une informatique plus flexible, créative et interactive, capable de répondre à nos besoins de manière plus naturelle et intuitive.Liens utiles :
Pourquoi l'architecture matériel Von Neumann n'est pas adaptée à l'IA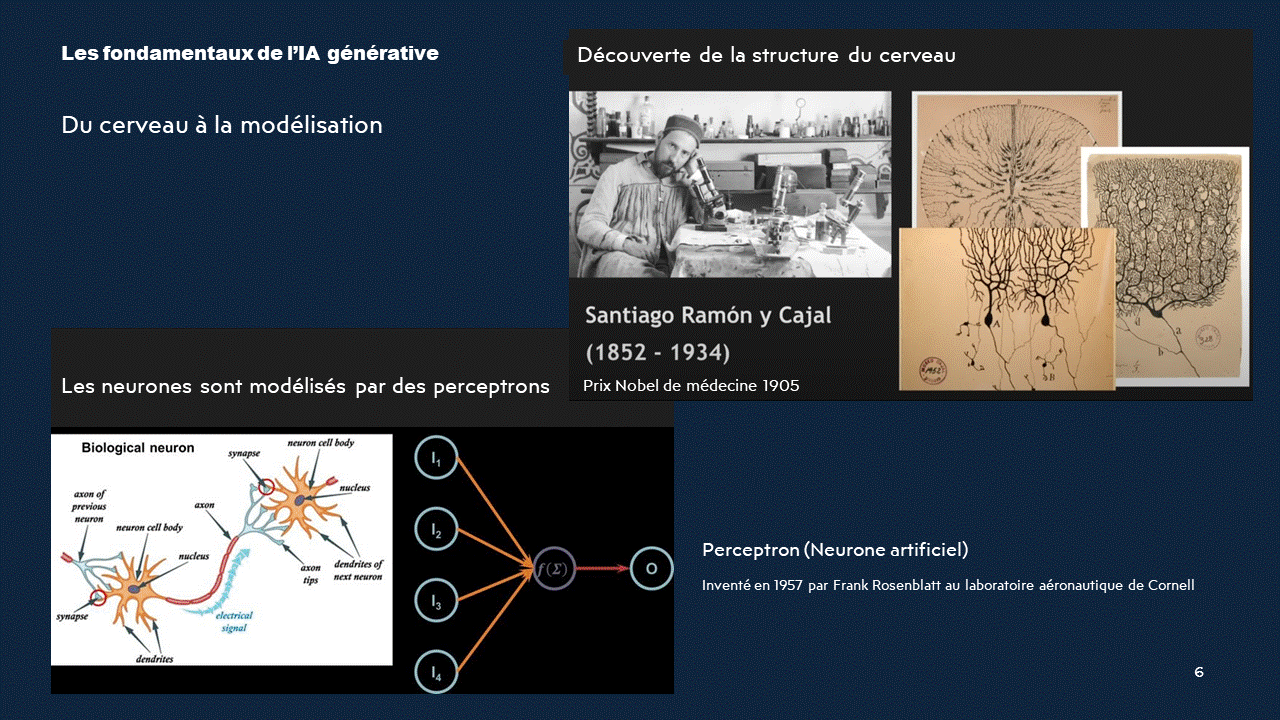
Modéliser le cerveau
La découverte de la structure du cerveau par Santiago Ramon y Cajal, prix Nobel de médecine 1905, a permis de mieux comprendre le fonctionnement du système nerveux.Cette connaissance a ensuite été utilisée pour développer des modèles mathématiques et informatiques des neurones, tels que le perceptron inventé par Frank Rosenblatt.
Le perceptron
Le perceptron est un modèle simplifié d'un neurone qui traite des signaux binaires et a joué un rôle important dans le développement de l'intelligence artificielle.Liens utiles :
Comprendre le mimétismeMarvin Minsky et l'IA
Nous allons maintenant entrer dans le coeur de la technologie IA.
Exemple d'illustration pour faciliter la compréhension des concepts IA - organisation d'une bibliothèque de livres
Modèles de base - Comment on fait que l'IA sache tout sur tout
LLM (Large Language Models) - Comment on spécialise l'AI sur un domaine particulier, tout en gardant les autres informations disponibles
Transformers - Le coeur de l'IA générative : comment l'IA inteprète les prompts et génère ses réponses
Bases de données vectorielles - Comment on organise le stockage des connaissances de l'IA
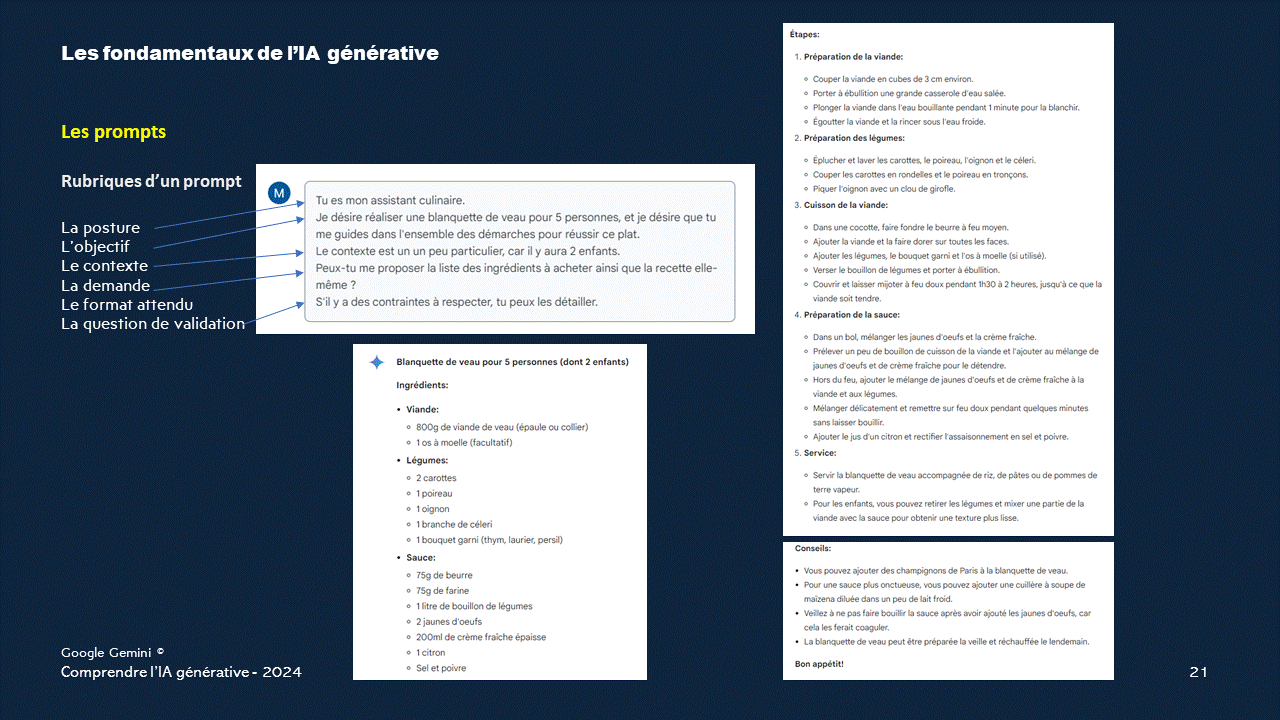
Prompts - Comment faire pour optimiser ses questions pour obtenir la bonne réponse

Illustration des concepts IA générative
Concevoir une bibliothèque

Modèles de base et apprentissage automatique
Les Grands Modèles de Langage (LLM) représentent une évolution des modèles de base, se spécialisant dans des domaines spécifiques par le biais d'une expansion de leur taille et de leur complexité. Cette spécialisation est obtenue grâce à un entraînement supplémentaire sur des ensembles de données plus vastes et variés, spécifiques au domaine ciblé.Le Fine Tuning est un processus où un modèle de base est ajusté pour répondre à des besoins spécifiques. Par exemple, un modèle général peut être affiné pour générer du contenu médical en s'entraînant sur des données médicales spécialisées, ce qui lui permet de produire des résultats plus précis et pertinents dans ce domaine.
Les données du Fine Tuning représentent les données STATIQUES peronnalisées
Quant au RAG (Retrieval Augmented Generation), il combine la recherche d'informations dans des documents et la génération de contenu issu du modèle de base. Par exemple, un chatbot médical utilisant le RAG peut d'abord rechercher des informations dans une base de données médicales, puis générer des réponses personnalisées en utilisant ces données comme base. Ainsi, il produit des réponses plus fiables et mieux informées en intégrant les connaissances préexistantes dans ses réponses.
Les données RAG représentent les données DYNAMIQUES personnalisées.
Liens utiles :
Fine-tuning de LLM : tout savoirRAG LLM : tout savoir
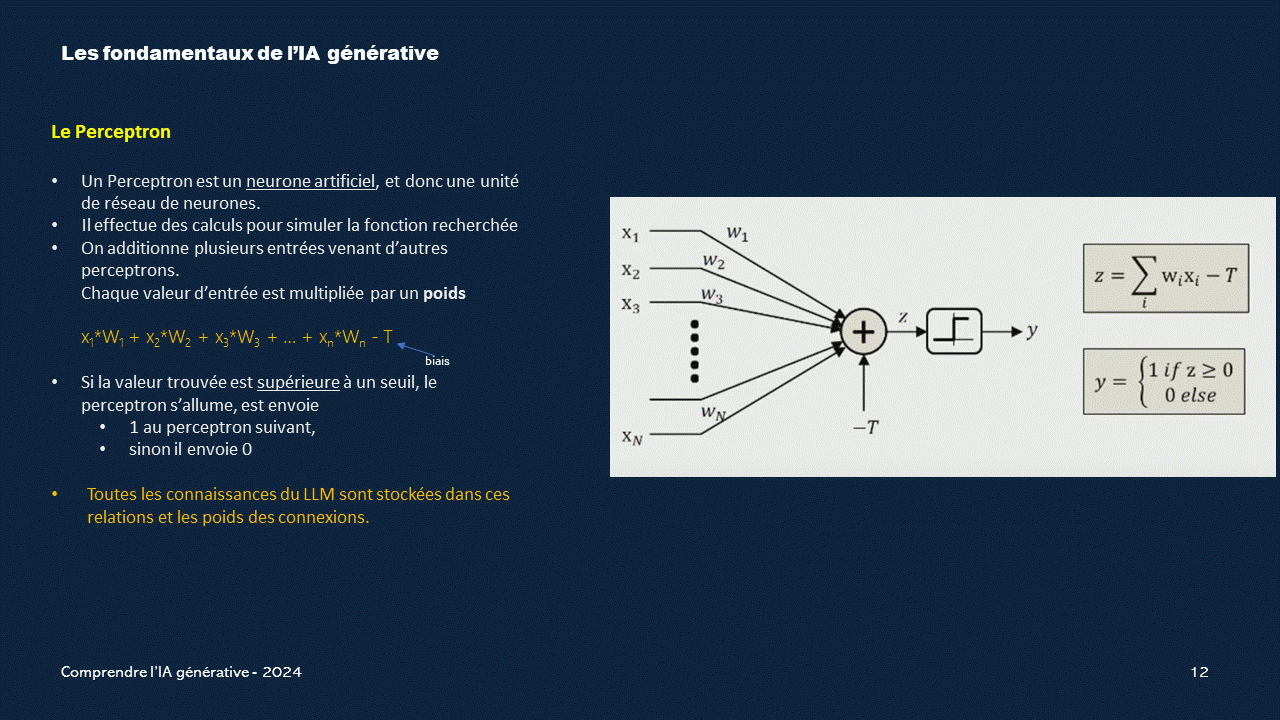
Le réseau de perceptrons
Le perceptron, bien qu'étant un modèle simple, joue un rôle important dans l'IA générative pour plusieurs raisons :1. Bloc de construction fondamental:
Le perceptron est l'unité de base des réseaux de neurones profonds, qui sont les modèles les plus utilisés en IA générative. En tant que tel, il est essentiel de comprendre le fonctionnement du perceptron pour pouvoir comprendre et construire des modèles génératifs plus complexes.
2. Apprentissage par rétropropagation:
Le perceptron est capable d'apprendre et d'ajuster ses poids grâce à l'algorithme d'apprentissage par rétropropagation.
Cet algorithme est utilisé dans tous les réseaux de neurones profonds, y compris les modèles génératifs.
3. Génération de données réalistes:
Les perceptrons sont reliés entre eux pour créer des réseaux de neurones qui peuvent apprendre à générer des données réalistes à partir d'un ensemble de données d'apprentissage.
Les poids,les connexions, les biais et les conditions d'allumage des perceptrons donnent la puissance et la flexibilité nécessaires à l'IA générative pour générer des images, du texte, de la musique et d'autres types de données..
Liens utiles :
LE PERCEPTRON - DEEP LEARNING (02)Le perceptron (premier réseau doté d'apprentissage)
Early History of Artificial Intelligence - Part 4 - Rosenblatt's Perceptron
MIT Introduction to Deep Learning | 6.S191
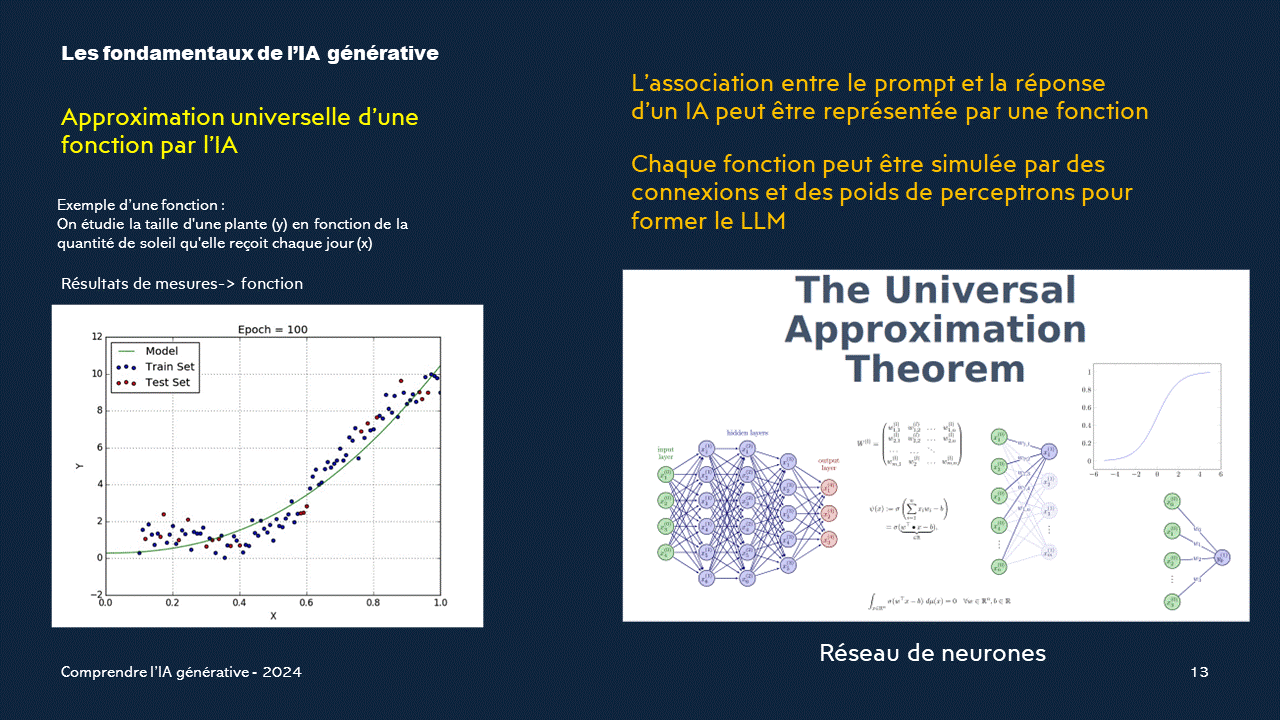
Le théorème d'approximation universelle
Ce théorème a des conséquences importantes pour l'apprentissage automatique.Il montre que les réseaux de neurones sont des modèles universels qui peuvent être utilisés pour résoudre une large gamme de problèmes.
Cela permet de modéliser des relations très complexes entre entrées et sorties.
Prenons comme exemple notre bibliothèque! Comment classer les livres par catégories.
On va préparer un tableau avec les caractéristiques (résumé, auteur, etc.) en entrées, et le catégories (romans, poésie, reportages...) en sortie.
Ce tableau pourra être représenté par des fonctions liant les entrées et les sorties.
Le théorème de l'approximation universelle, démontré par George Cybenko en 1989 et Kurt Hornik en 1991, stipule que les réseaux de neurones avec suffisamment de largeur et de profondeur, et des fonctions d'activation non linéaires, peuvent approximer n'importe quelle fonction.
On pourra donc simuler n'importe quelle fonction par un réseau de neurones. C'est ce théorème qui permet de comprendre pourquoi l'IA n'a pas de limites théoriques.
Liens utiles :
Universal Approximation Theorem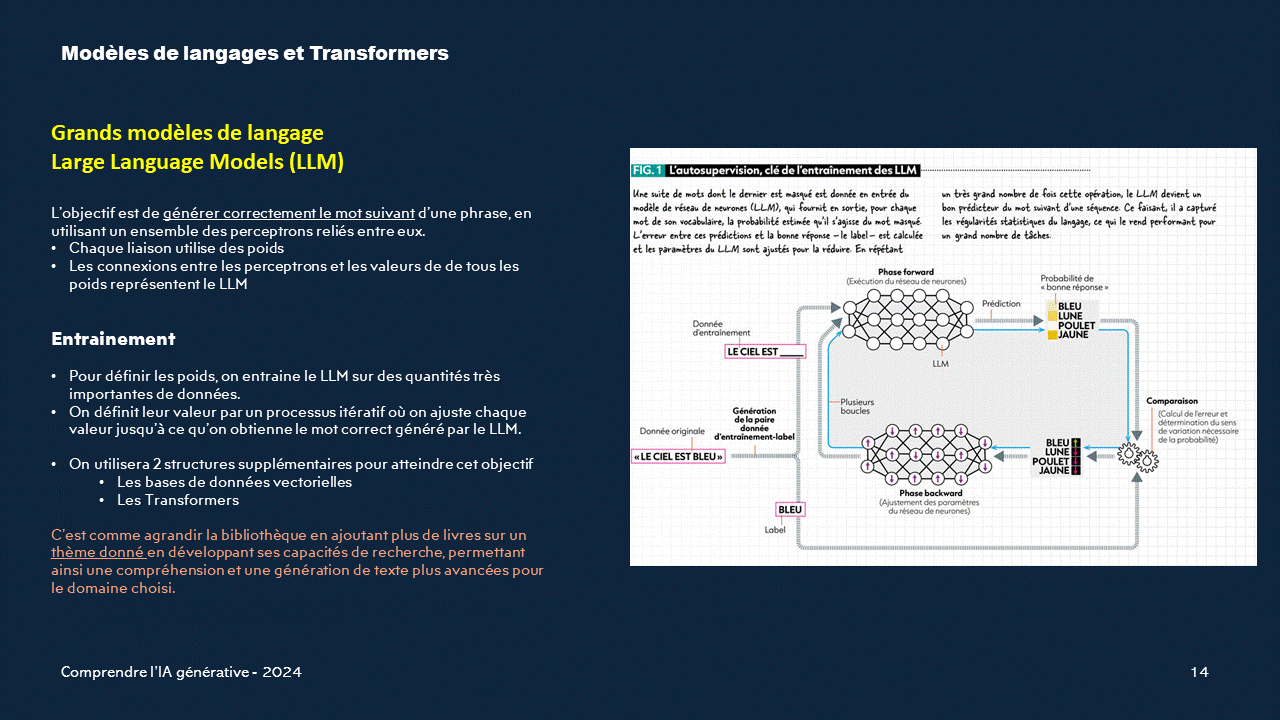
Objectif : Générer l'élément suivant
Toutes les techniques utilisées par l'IA générative n'ont qu'un seul but : Générer correctement l'élément suivant (texte, pixel, son...) à partir des informations disponibles.Moyens
On utilisera, pour atteindre cet objectif les techniques suivantes (entre autres)- L'entraînement des modèles de base
- L'utilisation de bases de données vectorielles (pour trouver les ressemblances entre les mots)
- Les Transformers (pour garder les contextes)
- Des analyses logiques entre les données
- Des méthodes mathématiques specialisées comme les chaînes de Markov
L'entraînement des modèles de base
L’entraînement consiste à exposer un modèle de base (Foundation Model) à des données d’apprentissage afin qu’il puisse apprendre à partir de ces exemples.Imaginez-le comme l’apprentissage d’un nouvel instrument de musique : plus vous pratiquez, plus vous devenez compétent.
L’entraînement permet à l’IA de généraliser à partir des données fournies.
Comment procède-t-on ?
Collecte de données
On rassemble un ensemble de données étiquetées (par exemple, des images de chats avec l’étiquette “chat”).
Choix du modèle : On sélectionne un algorithme d’apprentissage automatique (comme les réseaux de neurones) adapté à la tâche.
Entraînement : Le modèle ajuste ses paramètres (poids des perceptrons) en fonction des exemples d’apprentissage.
Validation : On vérifie que le modèle fonctionne correctement sur des données qu’il n’a jamais vues.
Utilisation : Une fois entraîné, le modèle peut être utilisé pour des prédictions (par exemple, classer des livres dans une bibliothèque).
Exemple : Organisation d’une bibliothèque
Entraînement : L’IA apprend à associer ces informations pour catégoriser les livres (romans, science-fiction, histoire, etc.).
Utilisation : Lorsqu’un nouveau livre arrive, l’IA peut le classer correctement en fonction de ses caractéristiques.
Liens utiles :
Training LLM GuideHow AI learned to talk
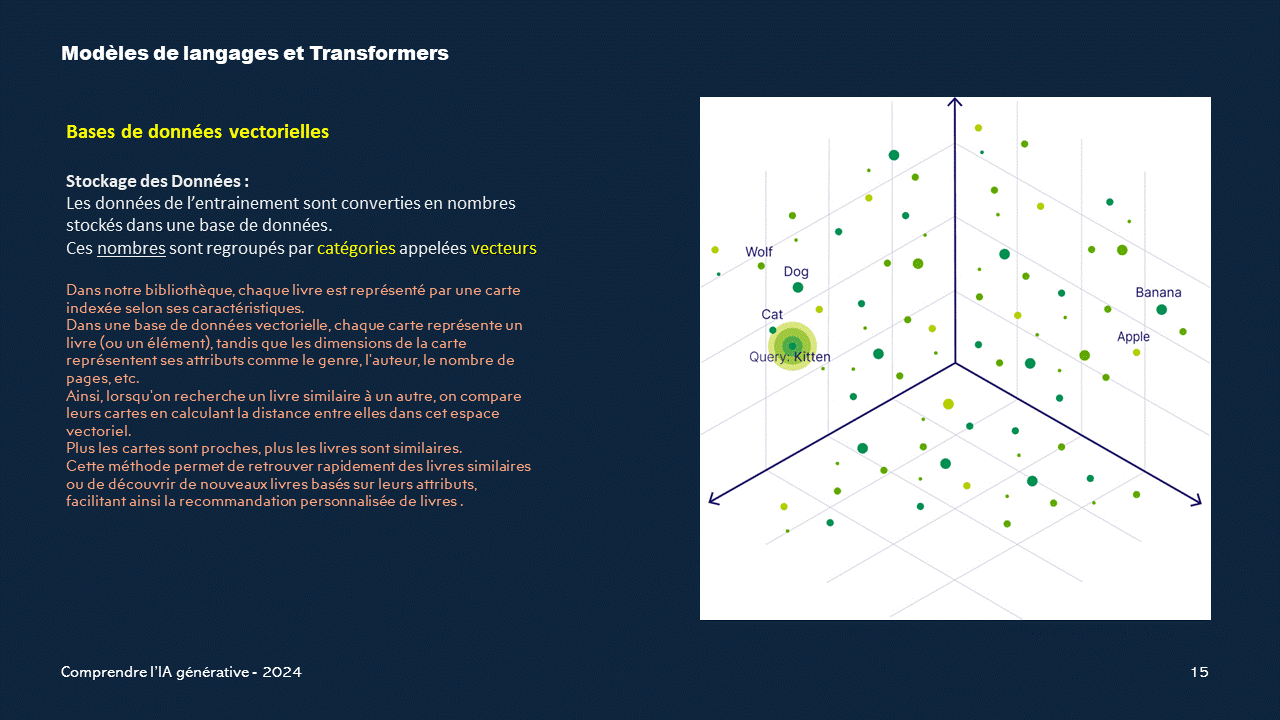
Les bases de données vectorielles pour l'IA
Les bases de données vectorielles sont un type de système de gestion de données conçu pour stocker et interroger efficacement des représentations vectorielles de données. Ces représentations vectorielles sont souvent utilisées dans les applications d'intelligence artificielle, en particulier pour le traitement du langage naturel et la reconnaissance d'images.Contrairement aux bases de données traditionnelles qui stockent des données sous forme de lignes et de colonnes, les bases de données vectorielles représentent les données sous forme de vecteurs, c'est-à-dire des listes de nombres.
Ces vecteurs capturent les caractéristiques sémantiques des données, de sorte que des éléments similaires se retrouvent proches les uns des autres dans l'espace vectoriel.
Exemple pour une bibliothèque
Imaginons une bibliothèque qui souhaite utiliser une base de données vectorielle pour permettre à ses utilisateurs de trouver des livres similaires à ceux qu'ils ont appréciés.Tout d'abord, la bibliothèque génère une représentation vectorielle pour chaque livre de sa collection, en se basant sur le contenu textuel, les métadonnées et d'autres caractéristiques pertinentes.
Par exemple, le vecteur du livre "Le Petit Prince" pourrait être quelque chose comme : [0.8, -0.2, 0.4, 0.1, -0.3, ...]
Ensuite, la bibliothèque stocke ces vecteurs dans sa base de données vectorielle, en les associant aux informations sur les livres (titre, auteur, résumé, etc.).
Lorsqu'un utilisateur recherche un livre qu'il a apprécié, la bibliothèque peut générer un vecteur de requête à partir des caractéristiques de ce livre.
Elle peut alors utiliser des techniques de recherche des plus proches voisins pour trouver les livres dont les vecteurs sont les plus similaires au vecteur de requête.
Cela permet de recommander à l'utilisateur des livres sémantiquement proches de celui qu'il a aimé, même s'ils n'ont pas de mots-clés en commun.
Cet exemple montre comment les bases de données vectorielles permettent de tirer parti des représentations vectorielles des données pour offrir des fonctionnalités avancées, comme la recherche par similarité, dans des applications d'IA comme une bibliothèque en ligne.
Liens utiles :
Bases de données vectorielles : la nouvelle révolution du Big DataCatalogue des bases de données vectorielles
Vector Database Explained | What is Vector Database?
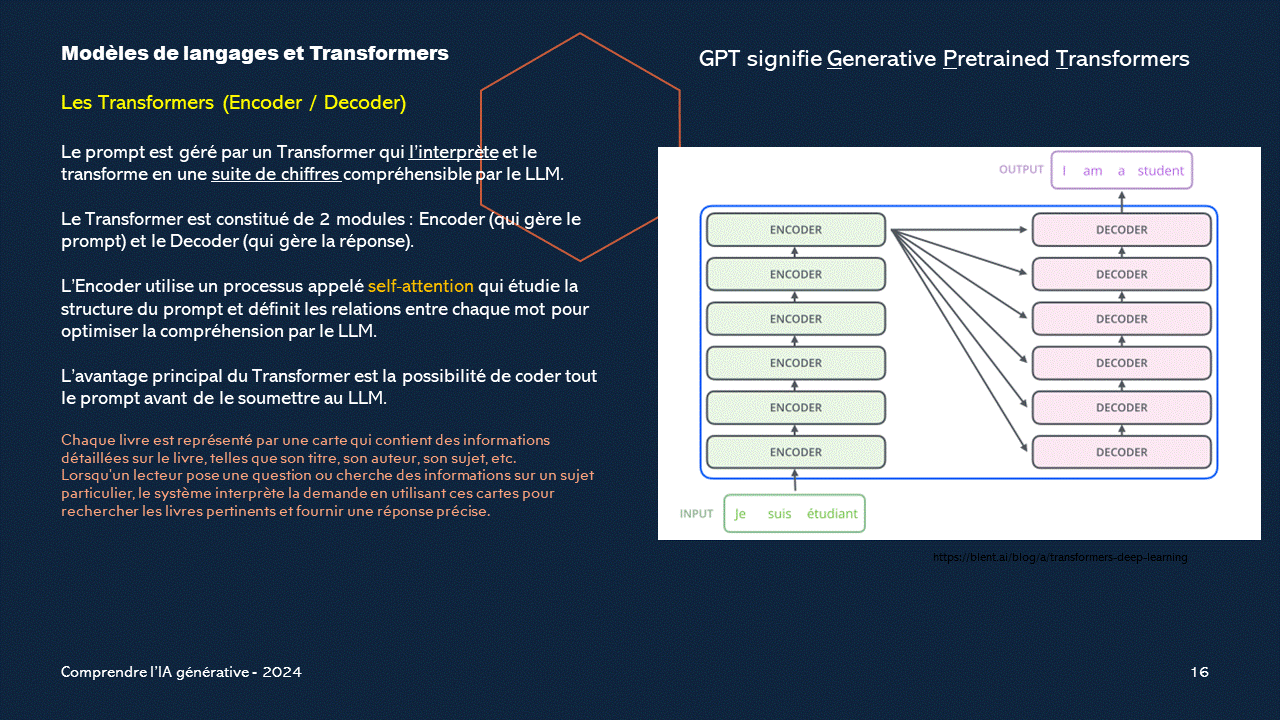
L'architecture Transformer
Les Transformers (Encodeur / Décodeur) Les Transformers sont des modèles d’apprentissage profond qui ont révolutionné le domaine du traitement du langage naturel (NLP). Ils sont basés sur l’article fondateur, publié en 2017 “Attention Is All You Need” de Vaswani et al1.L’architecture Encoder-Décodeur est l’une des variantes des Transformers, et elle est couramment utilisée pour résoudre des problèmes de séquence à séquence, tels que la traduction automatique et la génération de texte.
L’Architecture Encodeur-Décodeur
L’architecture Encoder-Décodeur se compose de deux parties principales : l’Encodeur et le Décodeur.
L’Encodeur
L’Encodeur traite la séquence d’entrée (par exemple, un texte en français) et génère une représentation cachée qui résume l’information d’entrée.Il est construit à partir de plusieurs blocs d’attention résiduelle, qui sont la pierre angulaire des Transformers.
Chaque bloc d’attention résiduelle utilise un mécanisme d’auto-attention pour capturer les relations entre les mots dans la séquence d’entrée.
L’auto-attention permet à l’Encodeur de prendre en compte tous les mots simultanément, ce qui améliore la compréhension contextuelle.
Le Décodeur
Le Décodeur prend la représentation cachée générée par l’Encodeur et génère la séquence de sortie (par exemple, la traduction en anglais).Il est également composé de blocs d’attention résiduelle, mais avec une attention différente appelée “attention causale”.
L’attention causale permet au Décodeur de ne regarder que les mots précédents dans la séquence de sortie, évitant ainsi les fuites d’information.
Le Décodeur génère un mot à la fois, en utilisant l’attention pour prédire le mot suivant.
Avantages des Transformers
L’avantage principal des Transformers est leur capacité à coder l’intégralité de la séquence d’entrée avant de la soumettre au Décodeur.Contrairement aux modèles RNN (réseaux de neurones récurrents), les Transformers n’ont pas besoin de traiter les mots un par un, ce qui accélère l’entraînement et l’inférence.
De plus, l’auto-attention permet aux Transformers de capturer des dépendances à longue portée entre les mots, améliorant ainsi la qualité des prédictions.
Liens utiles :
How Transformer workWhat are Transformer Models and how do they work?
Mais qu'est-ce qu'un GPT ? Introduction visuelle à Transformers
Présentation vidéo animée sur les Transformers
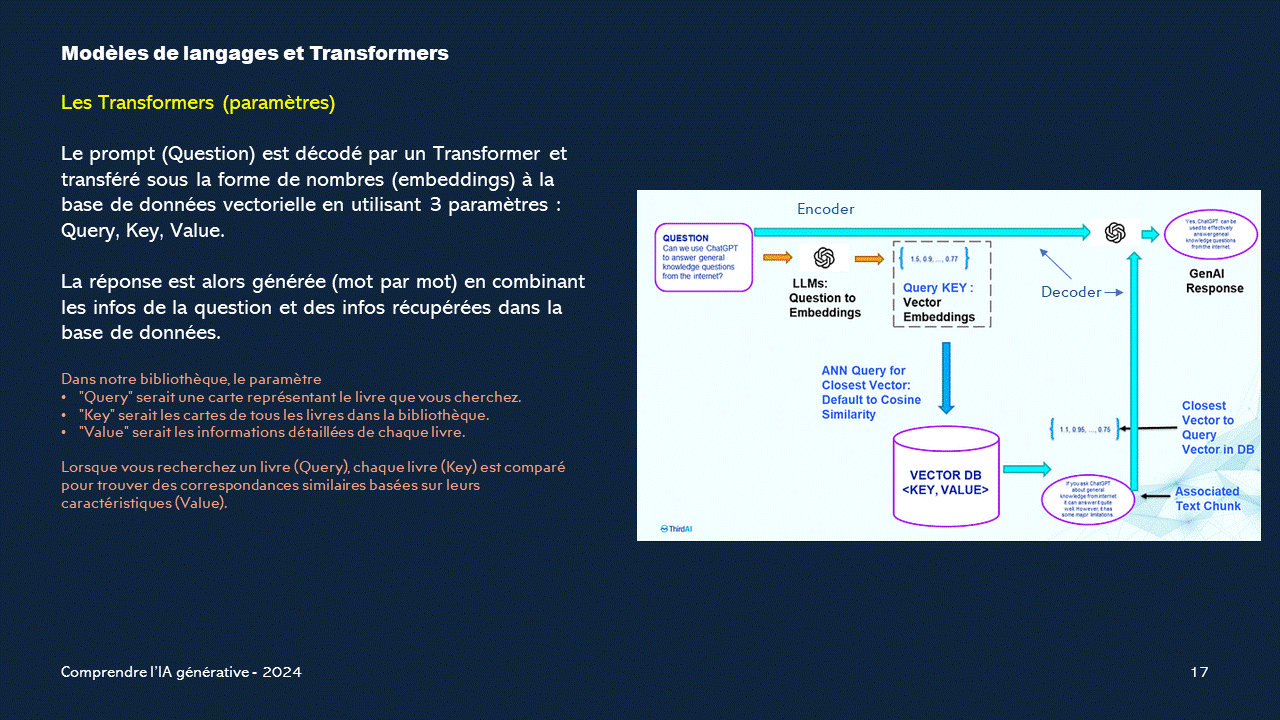
L'importance des prompts
Le traitement du prompt par le Transformer implique deux étapes principales : l'encodage et la génération de la réponse.Tout d'abord, le prompt est converti en une représentation numérique compréhensible par le modèle. Cette représentation est obtenue en divisant le prompt en morceaux appelés tokens, puis en les encodant à l'aide de vecteurs numériques.
Ces vecteurs, représentant chaque token, sont souvent tirés d'une base de données vectorielle pré-entraînée qui associe à chaque mot un vecteur numérique correspondant à ses propriétés sémantiques.
Ensuite, cette représentation encodée est transmise à l'Encodeur du Transformer.
L'Encodeur est chargé d'analyser la structure du prompt et de comprendre les relations entre ses différents éléments.
Pour ce faire, il utilise un mécanisme appelé auto-attention, où chaque token est associé à des vecteurs Query, Key et Value. Ces vecteurs permettent au Transformer de déterminer quels tokens sont les plus importants dans le prompt et de quelle manière ils interagissent les uns avec les autres.
Une fois que le prompt a été encodé et traité par l'Encodeur, sa représentation est transmise au Décodeur.
Le Décodeur utilise cette représentation pour générer une réponse en fonction du contexte du prompt.
Il utilise également des mécanismes d'attention pour prendre en compte à la fois le prompt et les tokens déjà générés de la réponse. Ainsi, le Transformer est capable de produire une réponse cohérente et pertinente en tenant compte du contexte du prompt.
En résumé, le traitement du prompt par le Transformer consiste à le convertir en une représentation numérique, à analyser ses relations internes à l'aide de vecteurs issus d'une base de données vectorielle, puis à générer une réponse appropriée en fonction de cette analyse et du contexte fourni.
Liens utiles :
The Attention Mechanism in Large Language Models









l'IA générative - comment ça marche ?
Cette présentation a pour objectif de comprendre les mécanismes internes de l'IA générative.
Nous aborderons uniquement l'IA générative de textes à partir de textes, sachant que le champ d'application est beaucoup plus vaste (images, sons, vidéos).
Bien que technique, cette présentation s'adresse à toute personne ayant une culture générale et qui n'est pas spécialisée dans ce domaine.
Voici le programme !